
机器学习概述
1、什么是机器学习
机器学习 ≈ 让机器帮我们找一个函数f解决某一问题。
如:
-
语音识别:

-
图像识别:
-
阿尔法
Go:

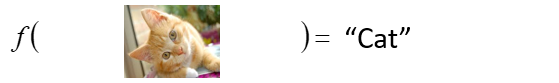
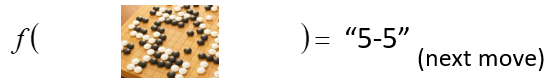
注:
- 本课程重点介绍机器学习(
ML,Machine Learning)中的深度学习(DL,Deep Learning); - 本课程主要介绍如何通过神经网络(
NN,Neural Network)的方式实现深度学习。
2、神经网络的输入和输出
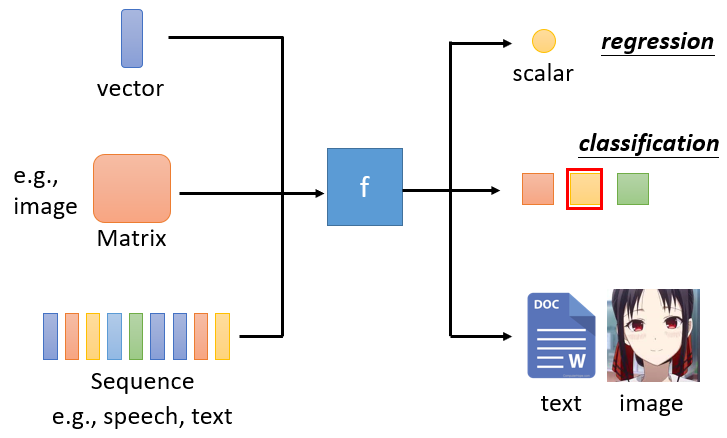
神经网络的输入可以是:
- 一个向量(
vector) - 一个矩阵(
Matrix),如:一张图片。 - 一个序列(
Sequence),如:一段语音、一段文字等。
神经网络的输出可以是:
- 一个数字(标量,
scalar),即是一个回归问题。 - 多个选项,即分类(
classification)问题。 - 其它复杂的输出,如:一段语音,一段文字、一个图片等。
3、课程概览
(1)第1-5讲:监督学习
监督学习(Supervised Learning)需要使用大量人工标记的数据作为训练集。
如:我们需要机器帮我们区分输入的图片是“神奇宝贝”还是“数码宝贝”。

那么,我们需要收集大量训练数据,并对所有的训练数据进行人工标注。

(2)第7讲:自监督学习
对样本进行标记需要耗费大量的人力和物力,实际应用中,不是所有任务我们都能够对训练数据进行标注。
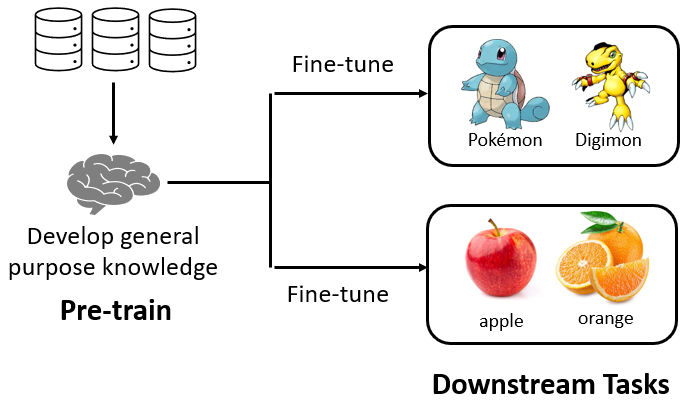
此时,我们可以通过自监督学习(Self-supervised Learning)的方式训练模型。即:在下游任务(Downstream Tasks)开始之前,在预训练(Pre-train)阶段先使用无标注的训练数据让模型学习基础知识,练好基本功,得到基础模型;当基础模型练好基本功后,我们只需对基础模型进行微调(Fine-tune)便可以完成某些下游任务了。
**如:**我们希望通过一个分类器同时可以区分“神奇宝贝”和“数码宝贝”、“汽车”和“自行车”、“猫”和“狗”、“苹果”和“橘子”。此时,我们不可能对所有的训练数据都进行标注。

此时,我们可以在预训练阶段,把一张图片左右翻转(或变色)后问机器它们是否一样。让机器通过这些完全没有标记的数据,自监督学习一些图像的基础知识。

当模型学会“图片左右翻转(或变色)后仍然是同一张图片”这些基础知识后,我们便可以通过微调该模型完成下游区分“神奇宝贝”和“数码宝贝”、“苹果”和“橘子”的任务了。
注:
-
预训练模型(
Pre-trained Model)与下游任务(Downstream Tasks)的关系类似于"操作系统"与"上层应用"的关系。 -
预训练模型(
Pre-trained Model),又称基础模型(Foundation Model)。 -
BERT(
Bidirectional Encoder Representation from Transformers)是一种目前广泛用于语言表征的预训练模型。

(3)第6讲:生成对抗网络
若我们想要使用监督学习模型,则需要输入成对的、作为训练数据。
但是,当我们掌握了生成对抗网络(Generative Adversarial Network,GAN)技术后,我们只需将可能的输入和可能的输出作为训练数据(并不需要输入成对的、作为训练数据),GAN模型便可以对把所有输入和输出的关系找出来,进而得到需要的机器学习模型。

**如:**语音识别

- 若使用监督学习模型,则需要将各语音信号及其对应的识别结果作为训练数据。
- 若使用生成对抗网络(
GAN)技术,则只需将大量语音信号和大量文本作为训练数据,输入的语音和文本可以互不相关。这样机器就可以自动学会语音识别。
(4)第12讲:强化学习
当我们在处理“不知道该如何确定训练集,只知道结果是好还是坏”的任务时,我们一般可以使用强化学习(Reinforcement Learning,RL)。
**如:**下围棋时,我们也不知道如何根据当前盘式判断下一步该下在哪,但我们知道下赢就是好、下输就是不好。

(5)第8讲:异常检测
异常检测(Anomaly Detection)就是让机器能够回答我不知道的能力。
**如:**当我们向区分“神奇宝贝(Pokémon)”和“数码宝贝(Digimon)”的分类器输入一个"霸王龙"时,机器应该说我不知道。

(6)第9讲:AI的可解释性
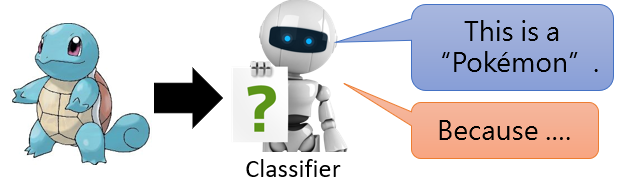
AI的可解释性(Explainable AI )就是让机器对其输出结果作出合理的解释。
**如:**让“神奇宝贝(Pokémon)”和“数码宝贝(Digimon)”的分类器告诉我们,为什么输入的“杰尼龟”是“神奇宝贝”。
(7)第10讲:模型攻击和防御
深度学习模型很可能会遭到恶意攻击,这些伪造的攻击对象对人类的判断没有太大影响,但会使模型输出意想不到的结果,造成误判。因此,我们需要对模型攻击和防御(Model Attack and Defense)技术进行研究。
**如:**先在原始图片上加入一定的噪音得到攻击图片(噪音放大50倍后如下图所示)。

然后再将原始图片和攻击图片分别输入到图像识别模型,有时可能会出现模型识别出错(把"猫"识别成“鱼)的问题。

(8)第11讲:领域自适应
一般我们在进行机器学习时,我们往往假设训练集和测试集的分布是类似的。但是,在实际应用中,测试数据往往来自于与训练数据不同的数据分布,即不同的领域(domain)。这种情况下,因为训练数据没有覆盖到测试数据的分布,模型在测试数据上的表现往往会大幅下降。因此,我们需要提升模型的领域自适应能力。
领域自适应(Domain Adaptation)是指通过学习源领域和目标领域之间的差异,来实现将源领域的模型迁移到目标领域的能力。
**如:**当使用手写识别模型时,若训练集和测试集分布相似(都使用黑白图片),则识别准确率较高;若训练集和测试集分布不同(使用彩色图片),则识别准确率可能会明显下降。

(9)第13讲:模型压缩
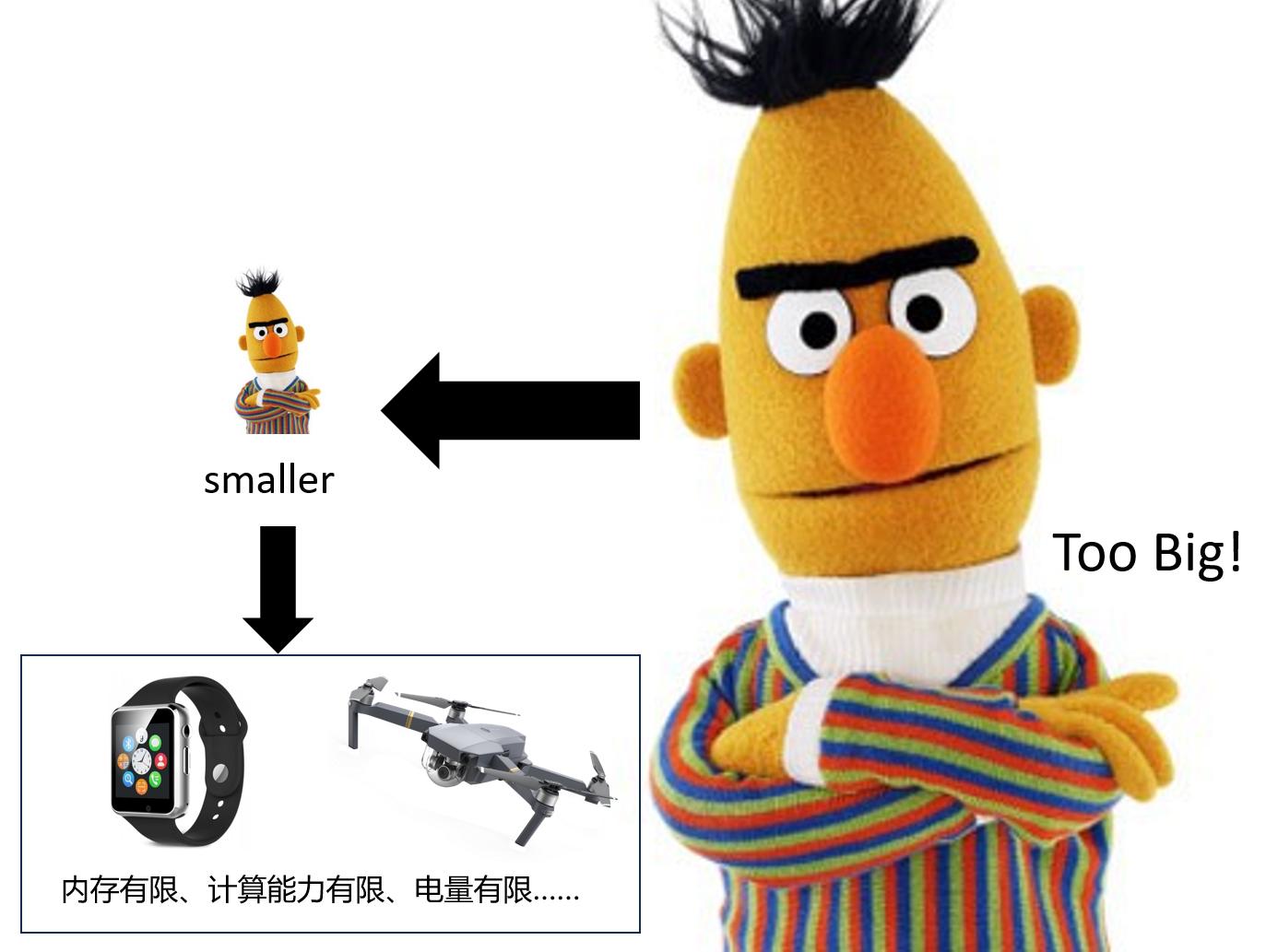
一般情况下,深度神经网络模型越深,非线性程度也就越大,相应的对现实问题的表达能力越强。但与此同时,训练成本和模型大小也随之增加。因此,为了能够在资源受限的环境(如:手机、手环、无人机、考勤机等)中部署ML模型,我们就需要进行模型压缩(Network Compression)。
(10)第14讲:终身学习
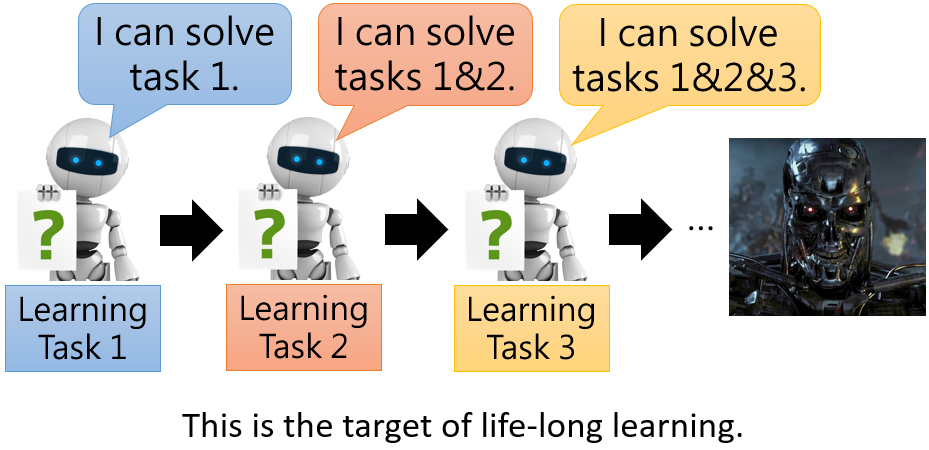
我们希望机器可以向人类一样可以进行终身学习(Life-long Learning),即:根据历史任务中学到的经验和知识来帮助学习不断出现的新任务。但实际工程中,想要机器能够实现终身学习,会遇到一系列问题和挑战。
(11)第15讲:元学习
元学习(Meta Learning)即:让机器学习如何学习(Learn to Learn)。
注:小样本学习(Few-shot learning)通常是通过元学习来实现的。
(本讲完,系列博文持续更新中…… )
参考文献:
[1] 《机器学习教程2021》,李宏毅
[2] 《机器学习教程2022》,李宏毅
如何获取资料?
关注 “阿汤笔迹” 微信公众号,在后台回复关键词 “机器学习” ,即可获取更多资料。

原文地址:http://www.atangbiji.com/2023/09/15/overviewOfMachineLearning/
博主最新文章在个人博客 http://www.atangbiji.com/ 发布。


